

Le mot d'introduction
2021 a encore été très perturbée par la pandémie avec toujours cette difficulté à nous retrouver physiquement lors de meetups. Néanmoins, notre choix de déplacer l’hackaviz et les rencontres de la dataviz le 1 octobre a été le bon puisque nous avons pu nous retrouver tous ensemble lors de cette unique occasion de l’année.
En 2021, nous avons réalisé :
- 5 meetups
- Les rencontres de la dataViz avec 4 conférences, un débat et une exposition de posters
- l’hackaviz 2021 et sa remise prix
- 2 interventions dans des classes de 4ᵉ d’un collège toulousain
- 9 newsletters
- 1 nouveau site web https://toulouse-dataviz.fr
Nous espérons que 2022 sera celle du retour des meetups en mode présentiel qui reste le meilleur moyen de se connaitre, de partager notre passion de la dataviz et d’élaborer des projets. Néanmoins, pour ne pas frustrer les participants non Toulousains qui ont pris l’habitude de nous suivre par vidéo en direct, nous essayerons de mettre systématiquement en place un mode hybride pour chacun des meetups à venir.
L’hackaviz reprendra ses quartiers d’hiver et aura lieu en mars 2022 et vous serez donc bientôt invité à vous inscrire.
L’année 2022 commence le 20 janvier avec le meetup “atelier de la dataviz”, un meetup très ludique qui vous permettra de confronter vos idées de graphiques à celle des autres.
Et bien sûr, plein d’autres événements et surprises à venir durant toute cette année.
Toute l'équipe du Toulouse Dataviz vous souhaite une très belle année 2022.
Meetup du 20/01/2022
Atelier Dataviz - Travail à faire à la maison
date et lieu à la Wild Code School - 19h
Description :
Pour la deuxième fois, Toulouse Dataviz et la Wild Code School organisent un atelier de dataviz ouvert à tous.
Venez exercer votre savoir en visualisation de données et confronter vos meilleures idées à celles des autres. Des sujets, qui malgré leur simplicité apparente, méritent que l’on y réfléchisse à plusieurs. Une série de jeux de données vous est proposée à l’avance :
- vous y réfléchissez à la maison et préparez une proposition (sur un outil ou papier crayon puis photo)
- vous partagez votre tentative sur le padlet TDV
- vous venez présenter votre proposition et découvrir celles des autres le 20 janvier 2022
- nous discutons ensemble des points forts et points faibles de chaque option
- vous apprenez des choses en s’amusant
Ce meetup est organisé en partenariat avec la Wild Code School de Toulouse qui forme des développeurs web et des Data Analysts.
S'inscrire ici
Comment mentir avec des graphiques... à l'ère de la post-vérité
“Comment mentir avec des graphiques”, c'est une présentation où Christophe Bontemps nous énumère quelques règles de visualisation pour s’amuser à produire des dataviz trompeuse. Christophe nous propose l'article Towards a Theory of Bullshit Visualization de Michael Correll. Ce dernier propose d'aller encore plus loin : le baratin (ou bullshit en bon anglais). Il ne s’agit plus de mentir, mais de renforcer une thèse fumeuse qui n'a que peu de rapport avec la dataviz. La visualisation devient alors une caution pseudoscientifique ou un assommoir. L'auteur du papier propose une classification non exhaustive illustrée par trois types de dataviz bullshit :
- un texte vaut mille images
- le sharpiegate ou le trait de plume vengeur
- l’époustouflante densité de données des dataviz militaires



Cartapaname, une expérimentation cartographique sur Paname.
Une fois n’est pas coutume, nous quittons l’Occitanie pour monter à la capitale. Cartapaname est une expérimentation cartographique sur la Ville Lumière. Découvrez une série de cartes de Paris dessinées par Maxime Salles, soutenu par Les Artisans Cartographes, lauréats du Mapathon 2020.


La bourse au plus haut
La bourse en 2021 : c’est descendu très bas et c’est remonté. En 2020, c’était plus calme, mais de grosses capitalisations se détachaient déjà du lot. Voici une dataviz qui résume la volatilité du S&P 500 (les 500 plus grosses capitalisations boursières aux Etats-Unis) en 2020. Ce graphe a été réalisé par Chartfleau en D3.js.

Les jeux olympiques d'été de Tokyo
Voici une bien étrange dataviz des médailles reportées par la Grande-Bretagne lors des jeux olympiques d'été Tokyo 2020 2021.

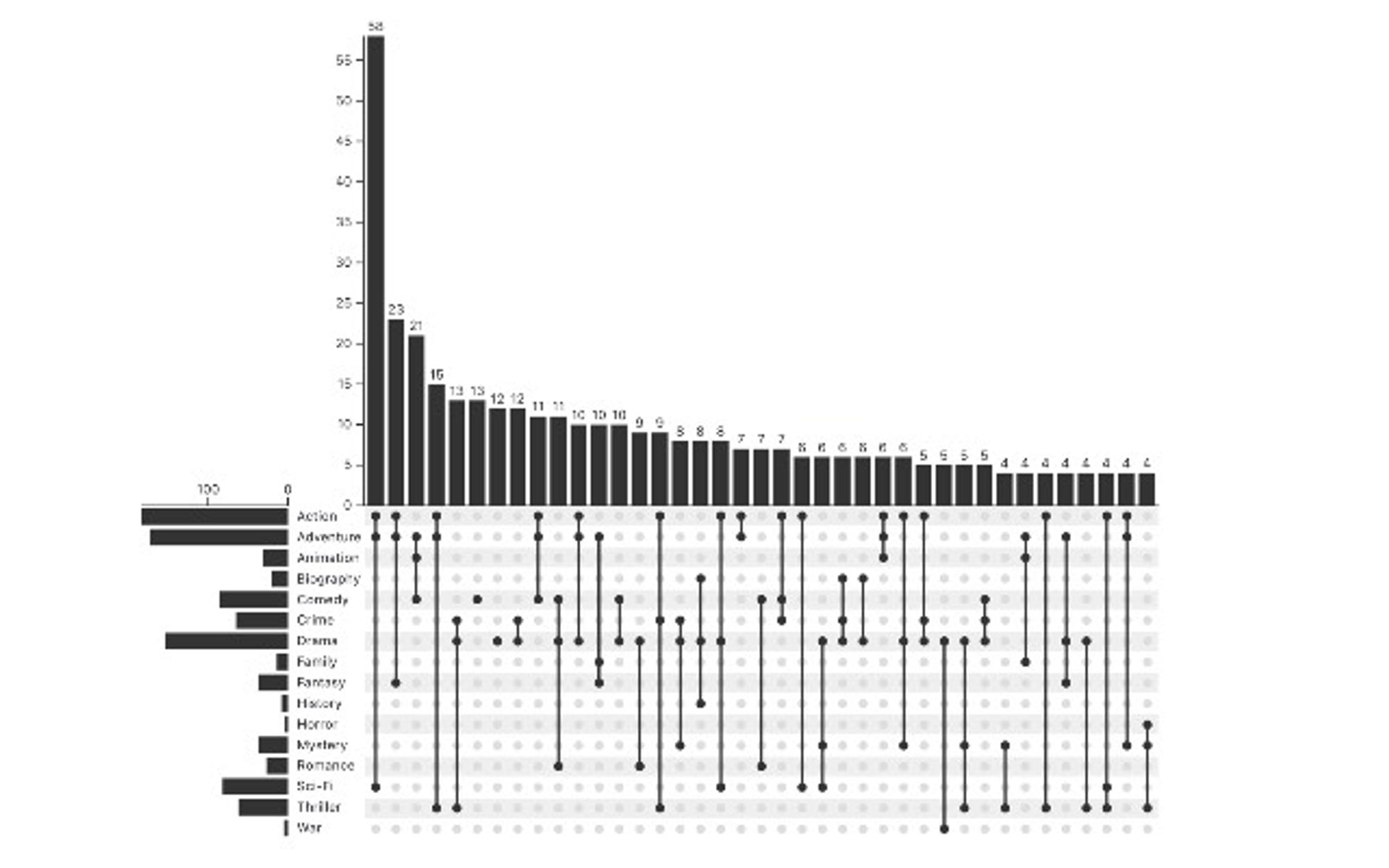
Upset diagram : visualiser les relations de plus de 3 ensembles
Comprendre les relations entre ensembles de données est vital. Cependant, au-delà de 3 ensembles, le vénérable diagramme de Venn ne passe pas trop à l’échelle. Que faire au-dessus ? Le diagramme upset est une superbe réponse, avec des exemples en R et en Plot.



L'actualité de l'Open Data : rapport minoritaire

Il y a 5 ans, la loi pour une République numérique, prévoyait la mise à disposition des jugements rendus par la justice française. Un décret plus tard, un calendrier est proposé. Pour l'instant : il n'y a que les décisions du Conseil d'Etat. En mars 2022, viendront s'y ajouter les décisions des cours administratives d'appel et en juin 2022, les décisions des tribunaux administratifs.
Les données sont disponibles sur ce site : https://opendata.conseil-etat.fr/ sous licence ETALAB 2.0. Cela reste laborieux : les jugements se présentent sous forme de fichiers XML dans lequel le jugement anonymisé est présenté sous forme d'un texte quasi brut, sans vraiment profiter de structure que pourrait justement apporter le format XML. Je suis rassuré "[l]es critères d’interopérabilité propres à l’open data (format XML) [ont été respectés] pour permettre la réutilisation et le partage de ces données par le plus grand nombre."
L’avènement de ces données permettra de nombreuses applications afin de calculer les chances de gagner un contentieux, estimer le montant des dommages et intérêts et pourquoi pas un jour, une justice prédictive, débarrassée de tout préjugé, grâce à une intelligence artificielle totalement objective ? Sauf que les résultats peuvent dépendre fortement du jeu de données et de réglages pouvant introduire un biais.
━━━━━━━━━━━━━━━━━━
Cette newsletter de Toulouse-dataviz a été rédigée avec l'outil Notion que nous aimons bien. Si vous lisez cette newsletter et que vous n'êtes pas encore inscrit au club, il vous suffit de cliquer ici. Pour se désinscrire, demandez ici. Toutes les anciennes newsletters sont consultables ici. Vous pouvez aussi rejoindre nos communautés : Club ou Discord.
Merci à nos sponsors Clever Age, Vector, Pierre Fabre, Etincelle et perceptible qui soutiennent nos activités.